






AI Agents for Infrastructure
Infrastructure management has always been reactive. Something breaks, an alert fires, an engineer wakes up, reads logs, runs a playbook, and fixes the problem. The industry spent the last decade automating the fix itself — Terraform, Ansible, Kubernetes operators — but the human in the loop never went away. Someone still has to decide what is wrong, what to do about it, and when to do it.
That is changing. AI agents — autonomous systems that observe, reason, and act on infrastructure without waiting for a human to tell them what to do — are moving from research demos to production environments. Not as chatbots that summarize your CloudWatch dashboards. As actual agents that detect a memory leak, correlate it with a recent deployment, roll back the offending service, and open a post-incident ticket before your on-call engineer finishes reading the first alert.
This is not a small change. It rewrites the operating model for every team that runs infrastructure at scale.
The term “AI agent” has been stretched to mean everything from a ChatGPT wrapper to a fully autonomous system that provisions entire environments. Let us be specific about what matters in the infrastructure context.
AnAI agent for infrastructure is a system that can:
1. Observe — continuously ingest signals from monitoring, logs, metrics, traces, and infrastructure state
2. Reason — correlate signals, identify root causes, evaluate possible actions, and predict outcomes
3. Act — execute changes against real infrastructure: scale resources, modify configurations, trigger deployments, remediate incidents
4. Learn — improve its decision-making based on outcomes of past actions and feedback from engineers
The critical distinction is between agents that recommend and agents that act. Most tools today are recommendation engines wearing an agent costume — they tell you what to do and wait for approval. Useful, but not transformative. The shift happens when the agent has the authority and capability to act autonomously within defined boundaries.
This is not about removing humans from infrastructure management. It is about removing humans from the 80% of operational work that is repetitive, well-understood, and follows patterns that an experienced SRE already has memorized. The human moves from executing the fix to defining the policy, reviewing the edge cases, and handling the genuinely novel situations.
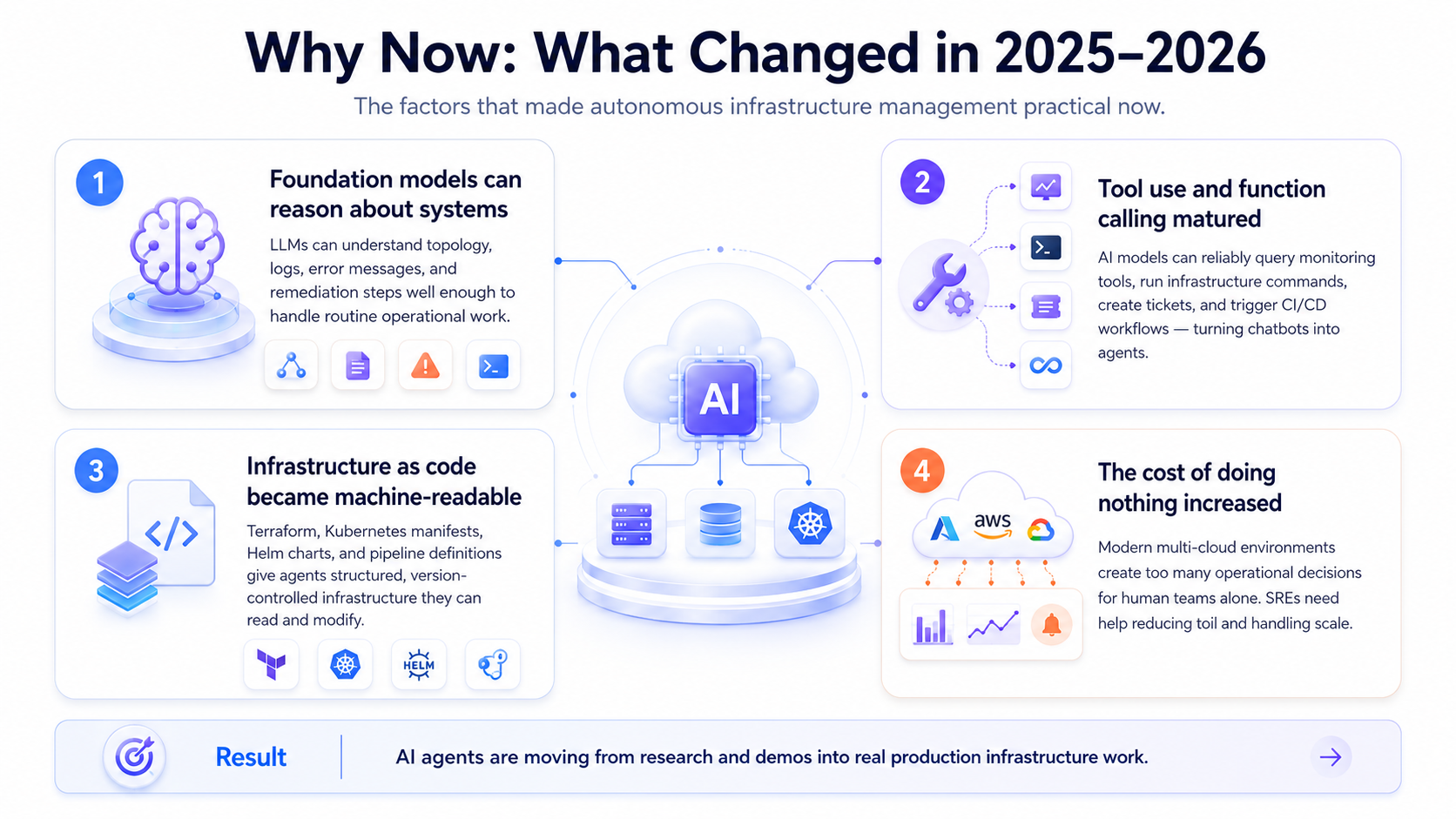
Autonomous infrastructure management has been a dream since the early days of DevOps.Several things converged to make it practical now.
Foundation models can reason about systems. Large language models are surprisingly good at understanding infrastructure topology, reading log output, interpreting error messages, and generating remediation steps. They are not perfect — but they are good enough to handle the routine cases that make up the bulk of operational work. When you combine an LLM with structured tools for querying infrastructure state and executing changes, you get an agent that can operate across the full stack without custom training foreach environment.
Tool use and function calling matured. The ability for an AI model to call external tools — query Prometheus, run akubectl command, create a Jira ticket, trigger a GitHub Actions workflow — went from experimental to production-grade in 2025. This is the mechanical capability that turns a chatbot into an agent. Without reliable tool use, you have a system that can talk about infrastructure. With it, you have a system that can manage infrastructure.
Infrastructure-as-code created a machine-readable substrate.Terraform state files, Kubernetes manifests, Helm charts, CI/CD pipeline definitions — the entire infrastructure stack is now described in structured, version-controlled files that an AI agent can read, understand, and modify. We spent a decade making infrastructure machine-readable for human operators. It turns out we were also making it machine-readable for AI agents.
The cost of doing nothing increased. Cloud environments are more complex than ever. A mid-size company runs hundreds of services across multiple clouds, each with its own networking, security, and scaling configuration. The number of operational decisions per day has outgrown what human teams can handle without burning out. The average SRE now spends more time on toil than on engineering. AI agents are not a nice-to-have — they are becoming necessary to operate at the complexity modern infrastructure demands.
Let us get specific. Here are the categories of infrastructure work where AI agents are already operating in production — not demos, not proofs of concept.
This is the highest-value use case and the one with the most traction. Traditional monitoring tells you something is wrong. An AI agent tells you why it is wrong and fixes it.
The pattern works like this: the agent continuously watches metrics, logs, and traces. When it detects an anomaly — elevated error rates, latency spikes, resource exhaustion — it does not just fire an alert. It investigates. It queries related services, checks recent deployments, examines configuration changes, and correlates the current symptoms with historical incidents.
If the root cause matches a known pattern, the agent executes the remediation:rolls back a deployment, scales up a service, clears a stuck queue, restarts a process. If the situation is novel or high-risk, it escalates to a human with a full diagnosis and recommended action.
The results are measurable. Teams running agent-based incident response report60–80% reduction in mean time to resolution for routine incidents, and a dramatic reduction in middle-of-the-night pages. The agent handles the 3 AM memory leak. The human reviews the incident report in the morning.
Cloud cost management is a perfect fit for AI agents because it requires continuous monitoring, cross-service correlation, and actions that are low-risk but high-effort for humans.
An infrastructure agent can identify underutilized resources, recommend or execute rightsizing changes, purchase reserved capacity or savings plans at optimal timing, terminate orphaned resources, and shift workloads between instance types or regions based on pricing changes. It can also model the cost impact of architectural changes before they happen — answering questions like “what happens to our AWS bill if we move this workload from on-demand to spot instances with a fallback.”
The difference between an AI agent and a traditional cost optimization tool is context. A rules-based tool sees a CPU averaging 5% and flags it. An AI agent understands that the instance is a build server that spikes to 100% during deployments, and that rightsizing it would break the build pipeline. Context turns a noisy recommendation engine into an actionable optimization system.
Security is another domain where the volume of signals has outgrown human capacity. The average cloud environment generates thousands of security-relevant events per day — IAM policy changes, network rule modifications, exposed ports, certificate expirations, vulnerability disclosures.
AI agents for security can:
• Continuously audit infrastructure against compliance frameworks
• Detect configuration drift from security baselines
• Identify overly permissiveIAM policies and generate least-privilege replacements
• Respond to security events with automated containment (isolate a compromised instance, rotate exposed credentials, block suspicious network traffic)
• Correlate vulnerability disclosures with the actual software versions running in your environment
The key advantage is speed. When a critical CVE drops, a security agent can scan your entire infrastructure, identify affected services, assess exposure, and begin patching — all within minutes. A human team doing the same work manually is measuring response time in hours or days.

Traditional autoscaling is reactive — it watches a metric, hits a threshold, and adds capacity. AI agents can do predictive scaling: analyzing historical patterns, upcoming events (marketing campaigns, product launches, seasonal traffic), and cross-service dependencies to provision capacity before it is needed.
More importantly, agents can handle the complex scaling decisions that simple threshold-based autoscaling cannot. When scaling a service requires also scaling its database, its cache layer, its message queue, and adjusting its rate limits — an agent can orchestrate the entire chain rather than scaling one component and waiting for the next bottleneck to appear.
If you are building or evaluating infrastructure agents, here is what the architecture typically looks like.
Perception layer. The agent needs to see your infrastructure. This means integrations with monitoring (Prometheus, Datadog, CloudWatch), logging (ELK, Loki, CloudWatch Logs), tracing (Jaeger, Zipkin),and infrastructure state (Terraform state, Kubernetes API, cloud providerAPIs). The more signals the agent has, the better it reasons.
Reasoning engine. This is typically a large language model — Claude, GPT-4, or an open-source model — combined with a prompt framework that provides context about your specific environment. The reasoning engine takes the current state, the problem description, and the available actions, and decides what to do.
Action layer. The agent needs hands. This means authenticated, scoped access to infrastructure APIs: Kubernetes, Terraform, cloud provider CLIs, CI/CD systems, ticketing systems. The action layer should enforce guardrails — maximum blast radius, required approvals for certain action types, rate limits on changes, and mandatory rollback plans.
Memory and learning. The agent needs to remember past incidents, past actions, and their outcomes. This is typically a combination of vector databases for semantic search over past incidents and structured databases for tracking action outcomes. Over time, the agent builds a knowledge base specific to your environment.
Guardrails and policy engine. This is the most critical component and the one most teams underinvest in. The guardrails define what the agent can do autonomously, what requires human approval, and what it should never do.
The biggest objection to AI agents managing infrastructure is trust. How do you give an autonomous system access to production infrastructure without it accidentally deleting your database?
The answer is the same way you handle it for junior engineers: graduated trust with clear boundaries.
Tier1 — Read-only and advisory. The agent can observe everything but change nothing. It monitors, analyzes, and recommends actions. A human reviews and executes. This is where every organization should start.
Tier2 — Autonomous for low-risk actions. The agent can execute changes that are easily reversible and have limited blast radius: scaling non-production environments, restarting stateless services, clearing caches, rotating non-critical credentials.
Tier3 — Autonomous for known patterns. The agent can handle incidents that match patterns it has successfully resolved before, including in production. Novel situations still escalate to humans.
Tier4 — Broad autonomy with guardrails. The agent can take most operational actions within defined boundaries. Humans focus on policy definition, architecture decisions, and genuinely novel situations.
Most organizations in production today are at Tier 2 or early Tier 3. The path toTier 4 is measured in months, not days.
• Blast radius limits. The agent cannot modify more than N resources in a single action.
• Rollback requirements. Every action the agent takes must have an automated rollback plan.
• Rate limits. The agent cannot make more than N changes per hour.
• Change windows. The agent can only make non-emergency changes during defined maintenance windows.
• Escalation triggers. Specific conditions that always escalate to humans: dataloss risk, security incidents, actions affecting customer-facing services above a traffic threshold.
• Audit logging. Every observation, decision, and action is logged with the agent’s reasoning chain.

On-call transforms. The 2 AM page for a known issue goes to the agent, not a human. The on-call engineer reviews agent actions in the morning rather than executing them at midnight.
TheSRE role evolves. SREs spend less time writing run books and more time writing agent policies. The skill set shifts from “knows how to fix the thing” to “knows how to teach the agent to fix the thing.”
Toil drops dramatically. AI agents are the first technology that can actually eliminate toil at scale rather than just automating individual tasks.
Team size decouples from infrastructure size.A team of five with well-configured agents can operate infrastructure that would traditionally require fifteen or twenty people. This does not mean teams shrink — it means they can manage more with the same headcount as the infrastructure grows.
Month1–2: Instrument and observe. Deploy an agent in read-only mode. Let it observe your infrastructure, analyze incidents, and generate recommendations. Compare its recommendations against what your team actually does.
Month2–3: Low-risk automation. Give the agent permission to handle non-production environments and low-risk operational tasks. Scaling, restarts, cache clears, certificate renewals. Every action gets reviewed by a human after the fact.
Month3–6: Expand to production for known patterns. Identify the top 10 incident types by frequency. Configure the agent to handle these autonomously in production, with guardrails. Track resolution time, success rate, and false positive rate.
Month6+: Continuous expansion. Gradually expand the agent’s scope based on demonstrated reliability. The agent’s capabilities grow as your trust in it grows, backed by data rather than faith.
Do not start with production autonomy. We have seen teams excited about AI agents give them production access on day one.This always ends badly. Start with read-only mode and earn your way to autonomy.
Do not skip the guardrails. An agent without guardrails is not autonomous — it is uncontrolled. Define clear boundaries before granting any action permissions.
Do not expect magic without observability.An AI agent is only as good as the signals it receives. If your monitoring has gaps, your logging is inconsistent, or your infrastructure state is not machine-readable — fix that first.
Do not build from scratch unless you have to.The build-vs-buy decision matters here. Evaluate existing platforms first and build custom only where they fall short.
Do not treat the agent as a replacement for understanding. The agent handles the execution, but your team still needs to understand the infrastructure. AI agents reduce toil — they do not reduce the need for expertise.
The trajectory is clear. Infrastructure management is moving from human-executed to agent-executed, with humans defining policy and handling exceptions. This is not a five-year prediction — it is happening now, in production, at companies that cannot afford to page an engineer for every known issue.
The organizations that adopt infrastructure agents early will operate at a different level of efficiency and reliability than those that wait. Not because the technology is magic, but because the problem — too many operational decisions for human teams to handle — is only getting worse as infrastructure grows more complex.
The question is not whether AI agents will manage your infrastructure. It is whether you will be the one defining the policies they follow, or whether you will be catching up to competitors who started six months earlier.
AtOpsWorks, we build and operate AI-powered infrastructure across multiple clouds. Whether you are exploring agent-based operations, designing guardrail frameworks, or scaling autonomous infrastructure management — we help you adopt this technology safely and effectively.
Ready to see how AI agents can transform your infrastructure operations?
Book a call with our team.



Subscribe to our newsletter and get the latest insights that help you stay ahead of the curve.

© 2017-2025 All rights are reserved


